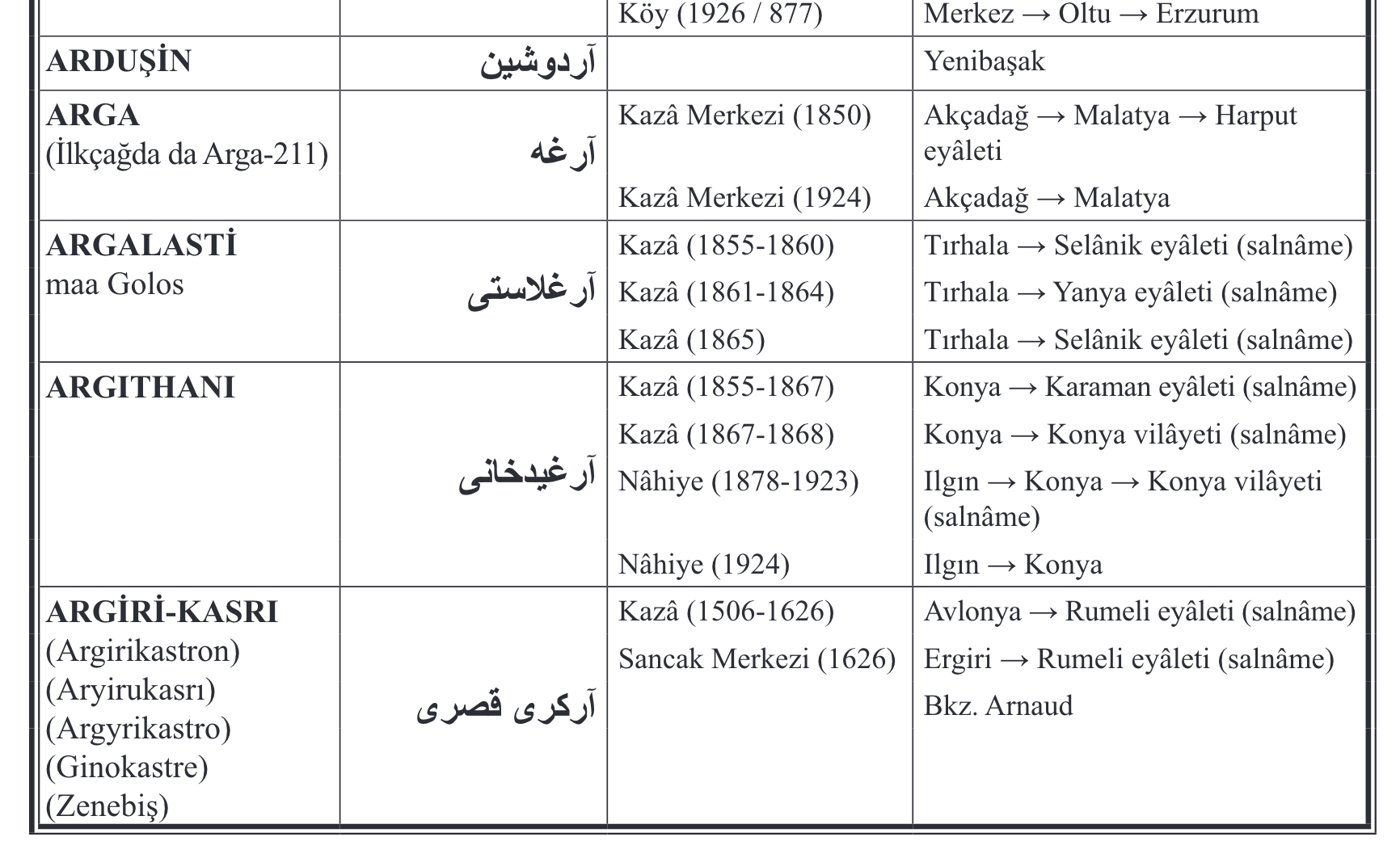
I’ve had to create one more non-RDF version, Ottgaz-data-9. This version reorganizes the data in a way I should have long ago. I had listed each place as its own row, with each successive reorganizations listed one after another, resulting in more than 100 columns and many empty cells. Now I’ve listed each place as its own record, with successive reorganizations listed one on top of the other. This means far fewer columns, which will make the RDF mapping much more efficient.
I used a concatenation/explosion technique to do this. I added a new column based on the first column in each numbered set of 10-11 columns (“Admin_unit_1”…“Belongs_to_1_1-code”). I used this GREL code to concatenate the columns (for example in the 7th series):
7 + "<>" + if(isNull(cells["Admin_unit_7"])," ",cells["Admin_unit_7"].value) + "<>" + if(isNull(cells["Admin_unit_7_start"])," ",cells["Admin_unit_7_start"].value) + "<>" + if(isNull(cells["Admin_unit_7_start_period"])," ",cells["Admin_unit_7_start_period"].value) + "<>" + if(isNull(cells["Admin_unit_7_stop"])," ",cells["Admin_unit_7_stop"].value) + "<>" + if(isNull(cells["Admin_unit_7_note"])," ",cells["Admin_unit_7_note"].value) + "<>" + if(isNull(cells["Belongs_to_7-4"])," ",cells["Belongs_to_7-4"].value) + "<>" + if(isNull(cells["Belongs_to_7-3"])," ",cells["Belongs_to_7-3"].value) + "<>" + if(isNull(cells["Belongs_to_7-2"])," ",cells["Belongs_to_7-2"].value) + "<>" + if(isNull(cells["Belongs_to_7-1"])," ",cells["Belongs_to_7-1"].value) + "<>" + if(isNull(cells["Belongs_to_7-1_id"])," ",cells["Belongs_to_7-1_id"].value)
I then faceted the results and deleted all of the 7 <> <> <> <> <> <> <> <> <> <> <> values, which were produced by a blank series of cells. After I’d done this for all 14 series, I deleted the atomized columns, leaving only these 14 concatenated columns. Then, after double checking that I was working with records rather than rows, I used the “transpose cells across columns into rows” command, transposing into one column and ignoring blank cells. I removed the 66,000-odd empty rows that resulted (filtering the concatenation column by blank). Finally, I exploded the contents of the resulting column, splitting into several columns using the <> separator.
The first time I did this, I thought I should record how I did it. I failed to do so, and perhaps as a result I managed to corrupt my file a few days later. I had to do the whole thing again (it took about half an hour), and this time I did document the process.
The resulting document contains twice as many rows (11989) but only 1/6 as many columns (25). I added a “sequence” column, ordering the succession of units for each place name in case I need this information later. I also added a “capitalized” boolean column. Sezen seems to have capitalized the leading placenames, but I won’t need this marker in my database. I’ve converted all the Uppercase names to Camel Case, but I’m keeping this marker in case I find I need it.