The initial data for this gazetteer is a transformed version of Tahir Sezen’s 1996 Osmanlı Yer Adları. This post documents how I transformed it and contains links to archived versions of the various stages of the transformation.
1. PDF to 3-column plain text spreadsheet
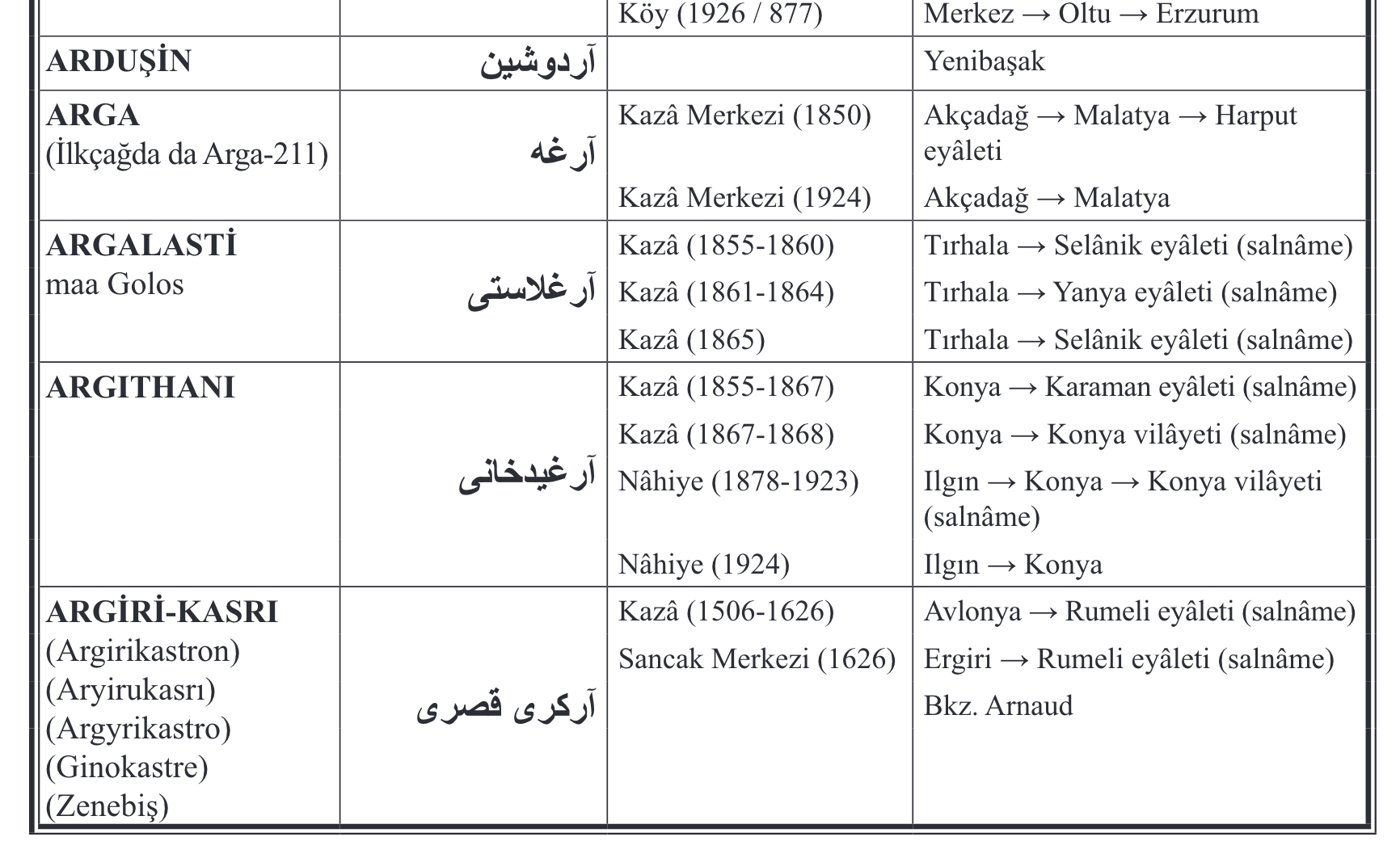
The first step was to extract a workable table from the OCRed version of the PDF. I copied the text of the Sezen pdf and pasted it into a word processor document. Initially this was challenging, because the multiple lines of the tables were not conforming to the column arrangement when imported into a spreadsheet. It took me a while to figure out a method, as I couldn’t seem to parse it by all caps or the alphabet switch. Luckily I realized that the font size of the Arabic-alphabet text differed. I used changes in font size to split the table into three columns: New alphabet name, old alphabet name, and a single field consisting of a long string describing the administrative classification of the place as well as the larger district containing it (Unvan ve Bağlı Olduğu Nahiye, Kaza, Sancak, Eyâlet veya Vilâyet). I used find and replace with the following regular expressions to create these tab-delineated lines:
- replace
$with#(to remove all line breaks) - delete
##[0-9]*(to remove page numbers) - replace
[[:::CharHeight=11::]]with\n&(to create a line break between each “new alphabet” administrative unit name, which are all given in 11pt font). - replace
[[:::CharHeight=12::]]with\t&\t(to create tabs before and after every “old alphabet” administrative unit name, which are given in 12 point foint).
For some reason these find and replace operations took forever in Libreoffice. When I broke the document into 8,000 word chunks, it went a lot faster. I pasted the results into a spreadsheet and cleaned up a few errors manually. There were about 6400 records in the table that resulted, which is archived as Ottgaz-data-1.
2. Creating columns
The next step was to produce a single line for each place listed, with every associated unit class/district (unvan/bağlı) pair broken out. I used OpenRefine to parse the columns before and after the unvan names, which were quite standard and limited in number. Almost half of the units are associated with only one class/district pair, which is to say they were only located under one date. At the other extreme, Kozan has 14 (!) pairs, which is to say that (according to Sezen) its administrative status changed 14 times over the history of the Ottoman Empire. It took a bit more than a day to do this. This version is archived as Ottgaz-data-2.
3. Breaking districts into multiple columns
Next I broke concatenated district entries (for example, İstefan→Sinop→Kastamonu→Kastamonu vilâyeti) into discrete ordered columns. This version (I think) is archived as Ottgaz-data-3.
4. Cleaning and standardizing
I then used OpenRefine to format and clean the data. This was a laborious process, and went through several iterations. I’ve archived all of these iterations as .tsv files and as OpenRefine projects, though I expect that they will be of little interest or use to anyone. This fourth iteration contains all of the bağlı hierarchical names in a single column, which is to say that it does not have a single row for each placename. It contains 38,465 rows. I used this method to standardize expressions of placenames and dates using OpenRefine’s clustering tools. This version, comprising 885 edits, is archived as Ottgaz-data-4.
5. Restructuring column hierarchy
The fifth iteration contains only one line for every place, and begins to elaborate the hierarchical structure. It stretches to 80 columns. I standardized the bağlı hierarchical language (which contained a lot of errors, some of which remain no doubt). I have given each nesting bağlı place name its own column, so, for example, İstefan→Sinop→Kastamonu→Kastamonu vilâyeti becomes 4 columns. These are numbered in hierarchical sequence: “Bağlı 1 1” is the smallest district containing the place in question (İstefan in this example), and Bağlı 2 etc are larger units. I have also broken out dates into their own columns, and standardized the titles (unvanlar), which will form part of the ontology of the gazetteer. Finally, I have amalgamated “unvan” notes and “bağlı” notes (anything other than a district type or a placename) into a single “notes” column. This version, comprising 873 edits, is archived as Ottgaz-data-5.
6. Translation of headings
The sixth iteration converts the headings into English, and continues the cleaning and standardization. I reversed the numbering of the containing units, so now Belongs_to_1-1 designates the largest unit. This version, comprising 454 edits, is archived as Ottgaz-data-6.
7. Introduction of database elements
The seventh iteration begins to implement some internal references, by adding a field for ID numbers, and beginning to reference IDs in the hierarchy. It also adds a Place_type field, differentiating between cities and regions, and an Ott_or_not field, a boolean category to isolate those records which situate the place in a hierarchy entirely outside of modern Turkey. This version, comprising 818 edits, is archived as Ottgaz-data-7.
8. Reconciliation and RDF skeleton
The eighth iteration, which I’m working on now, should be the last produced in OpenRefine. It integrates wikidata, geonames, and periodo references and contains an RDF skeleton. This version will be archived as Ottgaz-data-8.
Rough plans:
- I will combine rows which refer to the same place (many places are listed twice, under different names).
- I will give each administrative unit a number
- I will align the dates with a periodization of sultan’s epochs that I created on PerioDo.
- I will substitute the appropriate number for each “containing district” (bağlı olduğu…) field
- I will produce an RDF skeleton and export the data, conforming to the Pelagios Gazetteer Interchange Format
- I will wrangle this onto the [ottgaz.org] server, using OntoWiki at least initially